

Announcing Edison 2, with Group Experiments and Quantitative Data!

I am absolutely thilled to let you know that Edison 2 is live. It adds two major features: Group experiments and quantitative data. A little about each follows below. I've also added a list view for experiments, which helps to get a sense of the different kinds of activity going on, especially what new group experiments have been created, and which ones you might want to join.
I threw together some documentation on the thinktrylearn.com wiki at EdisonHelp, with screencasts hopefully coming soon. As an experiment, I'm playing with using Edison itself to document how to use it, in the form of an Official Group Experiment. (Note: If you're interested in volunteering, I have plenty of fun ways you can help with Edison, including documentation and screencasts.)

For the development philosophy, I worked hard to adopt the edict of "As simple as possible, but no simpler"[1], part of the lean startup ideas I'm learning about. Here I kept the functionality and designs of the two features to a minimum, including converging on a super simple data model. Like any good experiment, the results will tell me how I did and where to go next.
A huge thanks to my brilliant back end programmer Andy O'Shea, and to and my talented designer and front end coder Zinj Guo. They are both excellent, and made this ambitious release go smoothly.
In the next week or two I'll be announcing a contest with prizes for various categories, such as experiment with the most participants, most data, or experiment with the most surprising results. Stay tuned, and Happy Experimenting!
Group Experiments
![]()
There are now basically two experiment types - Individual Experiments and Group Experiments. They are created by the "Create an Experiment" button that's at the top of the right sidebar on most pages, which now pops up a choice of which type you want to create. Individual experiments haven't changed in concept, but they now - like any experiment - have the option of defining measurements that are used for capturing data about your experiment.
Group experiments, on the other hand, are community experiments that multiple people participate in. The way they work is straightforward. You create a group experiment (describing its details and defining its measurements), which people can join by clicking the big "Join" button at the top right of the group experiment's page. Participants who join get an personal instance of the group experiment (called a "peer" experiment) that works like an individual one, but which is linked to the group. In this way you get to make observations and record data on your own experiment page, but you can also interact with the rest of the group by making comments on the group experiment's page. In other words, it's the community page for the group experiment itself.
You can read more in the docs. Again, comments are always welcome.
Quantitative Data
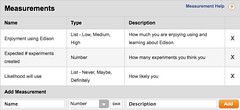
The other big feature is the ability to define what measurements you'd like to take in your experiment. The way you do this is to edit the experiment's details and use the Measurements widget at the bottom to specify each thing you want to track. The data model I decided on is simple:
From DesigningExperiments: Each measurement has four components:
- Name: A few words at most
- Type: Either Number or List
- Units: What units the measurement is in (optional)
- Description: What the measurement is, what it's used for, how and when the measurement is taken, etc. (optional)
This should cover 90% of all measurement tasks, with some work-arounds for the others. (Again, the results of the 2.0 release will tell me a lot.) Once you've defined your measurements you can enter data anywhere you could enter a text observation before. There's also a dedicated Data page for browsing, editing, and deleting.
 Matthew Cornell
Matthew Cornell


